每日论文: MoM: Linear Sequence Modeling with Mixture-of-Memories #20251110
模型架构
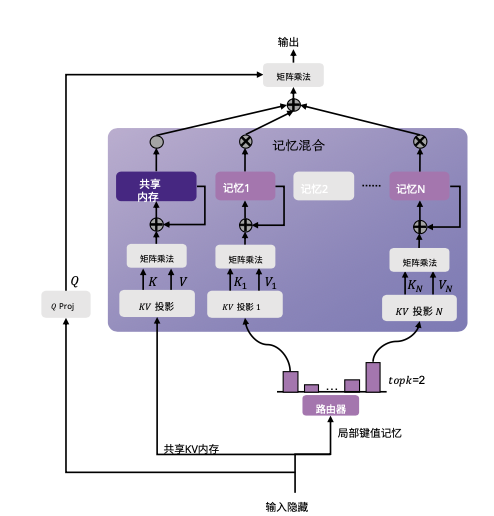
将MoE的思想搬到线性注意力上,用一个线性层为输入生成分数,然后选择top-k个记忆进行线性注意力计算.对于每个记忆,使用和计算线性注意力相同的方式计算,最后将多个记忆的结果进行加权求和.(权重是归一化后的top-k分数)
共享内存被一直使用,保证完整历史上下文.
计算优化(非本文创新)
类似flash-linear-attention,将计算拆分成多个chunk进行计算,并使用累积和来避免重复计算.
并行扫描
linear attention的计算可以看成rnn,即每一步的输出依赖于前一步的输出.
对于gpu上的并行训练,模型先对所有token计算路由,按照记忆划分将token分组扁平化存储,然后对每个记忆分别进行并行扫描计算,最后将结果重新组合.
细节
根据rnn性质,支持$$f(f(M_i, A), B) = f(M_i, A ⊕ B)$$,即可以根据之前的信息进行合并拿到结果.
所以第一阶段所有token分别并行计算更新量(对于线性注意力,有$$\Delta = \phi(k_t)v_t^T$$ ),而接下来就是要合并,考虑到每个单独去合并会有大量重复计算,因此使用树状的结构,每次合并相邻的两个块,然后再将合并后的块继续合并,直到最后得到最终结果.